 The industrial partners Mercateo AG, chemmedia AG and deecoob Technology GmbH, together with the Technische Universität Dresden (TUD), worked on the joint R&D project “Visual Analytics Interfaces for Big Data Environments – VANDA” in the period 2016 to 2019. The aim of this project was to address the so-called four “V´s” – Volume, Velocity, Variety and Veracity – as the challenge of Big Data driven interfaces and applications. The research work was carried out both in the backend area, i.e. the efficient processing of Big Data, and in the frontend, i.e. the intuitive visualization of Big Data. In the course of the project, best practice solutions for visualization and backend processes were researched, developed and implemented in the form of demonstrators.
The industrial partners Mercateo AG, chemmedia AG and deecoob Technology GmbH, together with the Technische Universität Dresden (TUD), worked on the joint R&D project “Visual Analytics Interfaces for Big Data Environments – VANDA” in the period 2016 to 2019. The aim of this project was to address the so-called four “V´s” – Volume, Velocity, Variety and Veracity – as the challenge of Big Data driven interfaces and applications. The research work was carried out both in the backend area, i.e. the efficient processing of Big Data, and in the frontend, i.e. the intuitive visualization of Big Data. In the course of the project, best practice solutions for visualization and backend processes were researched, developed and implemented in the form of demonstrators.
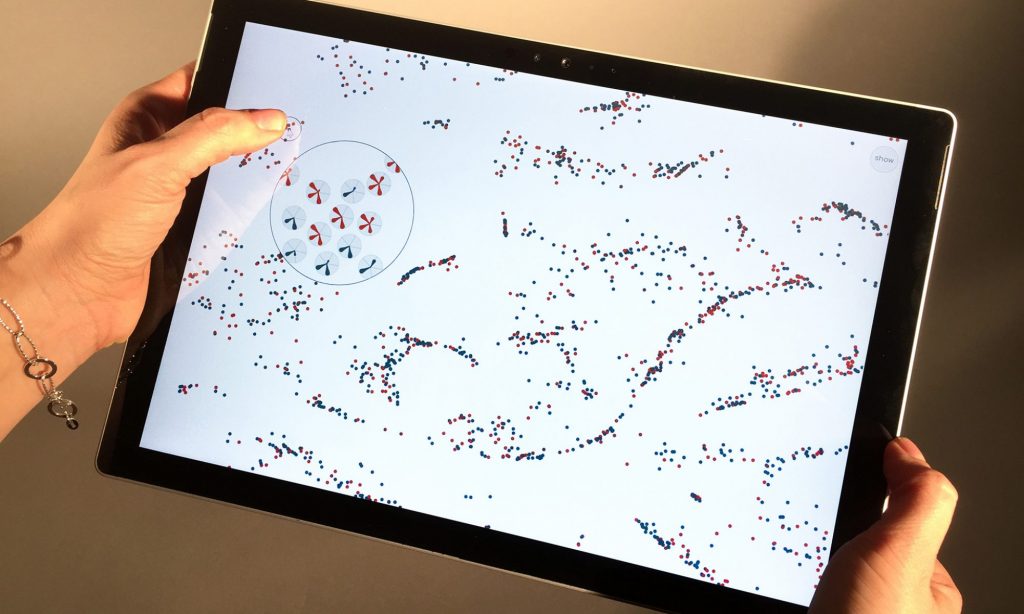
After an extensive technology and scientific research, the first step of VANDA project was to build a data processing pipeline as a cloud solution from AWS with Docker as container solution. Furthermore, the project partners developed their own data processing pipelines. Together with TUD, deecoob planned and carried out a qualitative glyph study to check the suitability of different glyphs. The strengths and weaknesses of the glyph visualizations varied depending on the data set used and the characteristics and values of individual features. For this reason, different glyph variants were used in the following visualization solutions. Based on the results of this study, the Glyphboard demonstrator was developed and implemented, which is based on the Glyph variants “Flower-Glyphe” and “Starplot”. Subsequently, a second study was carried out to test how different users can work with the offered functionalities of the Glyphboard demonstrator.
In a next step, the project partners addressed the challenge of displaying multidimensional data sets in web browsers with the purpose of optimizing performance. This can be done using technologies such as SVG, Canvas and WebGL. The WebGL rendering for a WebGL demonstrator was implemented using the framework three.js. In addition, various input and output media were examined for their suitability for the visualization of large data sets and implemented as demonstrators (e.g. multitouch display, elastic display, virtual reality with head-mounted display and touch controllers). For the automated evaluation and qualification of event advertisements in social media and other digital sources, deecoob has dealt with the entire processing chain from web scraping through information extraction on to classification. It could be proven that it is possible to represent and process several different languages in one text classifier model. Tests have shown that a classifier (ensemble classifier from different neural networks) can be trained with Swedish, French, Danish and Dutch texts based on the BERT language model and is even able to classify Hebrew event texts in a meaningful way.
deecoob has also successfully implemented and tested a new developed algorithm (Revised Sample Selection) for training data selection as well as a workflow for annotating the data by several test persons in an Active Learning demonstrator. The topic of information extraction was then considered in the project with reference to several application areas, e.g. identification of artist names from unstructured web data. This showed that different approaches make sense depending on the application context.
In the near future we will continue developing and implementing the partial components, which were developed within the framework of demonstrators during the VANDA project, and integrate them step by step into our productive platform deecoob insight and our business applications like MESLIS. These are in particular the components for text analysis such as PoS taggers, which are used especially for the recognition of proper names (NER), index databases (NoSQL) for certain information retrieval tasks or specially developed demonstrators for data annotation and analysis.
The research project was funded by the European Regional Development Fund. It was very successful for all three companies involved and TUD. The project team could even attend some international high-level conferences, publish some important research papers and support some students with research work for bachelor, master and PHD thesis.
We are very happy about the intention of all partners to start a new project together in the near future. This new project will pretty much focus our joint research and development activities on specific topics within Artificial Intelligence and machine learning like the “black box problem”, which has already been formulated in general terms and explored in research through topics such as Explainable Machine Learning and Artificial Intelligence Explainability. The goal of Explainable AI (xAI) is to develop a set of new or modified machine learning techniques that produce explainable models. In combination with effective explanation techniques, users will then be enabled to understand, trust and effectively manage the new generation of AI systems.
